暗号資産の定額積み立てサービス「Zaifコイン積立」を使用している方は、確定申告向けの損益計算のために購入履歴を集計する必要があります。
しかし、取引履歴等とは異なりCSV出力機能がないため、コピペが必要で非常に手間がかかります(参考URL)。
そこで、コピペを不要とし時間が短縮できるスクリプトを作りましたので共有します。
皆様の税金計算を少しでも楽にできれば幸いです。
概要
本記事のスクリプトを用いたデータ収集の流れは以下になります。
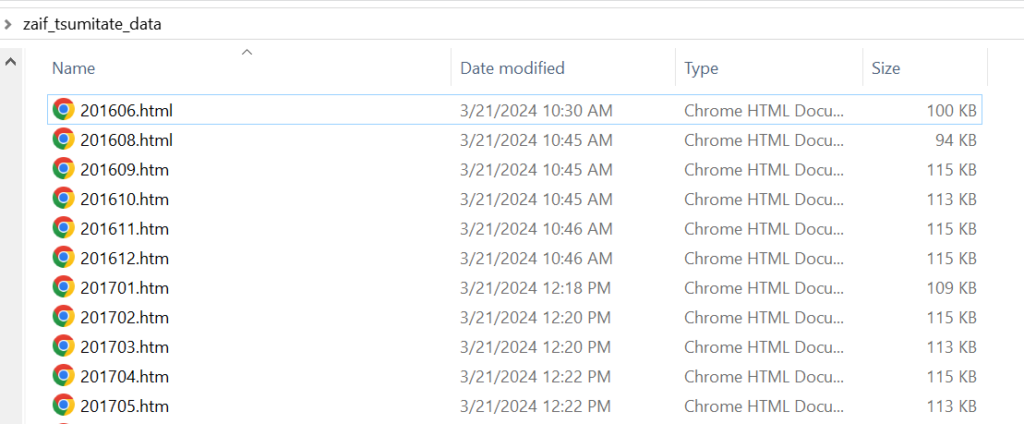
Zaifコイン積立ページの「積立履歴の確認」から、各月の明細をHTML形式のままダウンロード
STEP1で取得したHTMLファイルを自動でスクレイピングし、1つのCSVファイルにまとめる
Zaifからの積み立て履歴の確認ページ取得
Zaif にログインします。
中ほどにある、「Zaifコイン積立」をクリックします。
「銀行口座の積立履歴」をクリックすることで、積立履歴の確認ができます。
下側にあるメニューで取得したい履歴のある年度に移動します。
以下の様に、月ごとの引き落とし金額と積立額、手数料が表示されます。
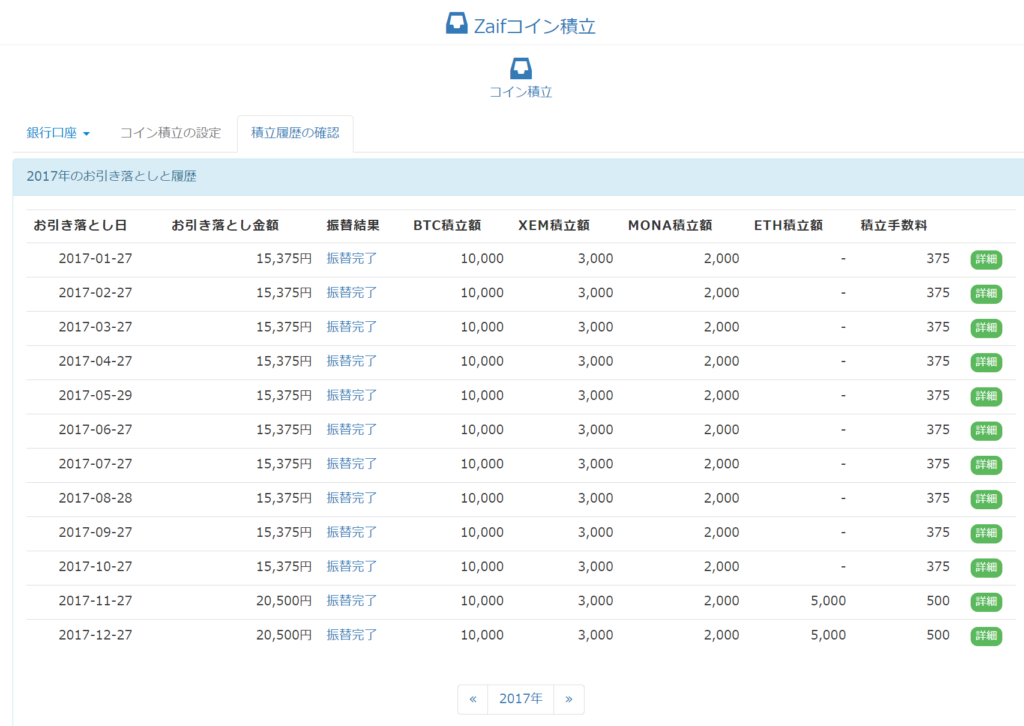
ここで、右にある緑のボタン「詳細」を右クリックし、「名前を付けて(リンク先を)保存」をします。
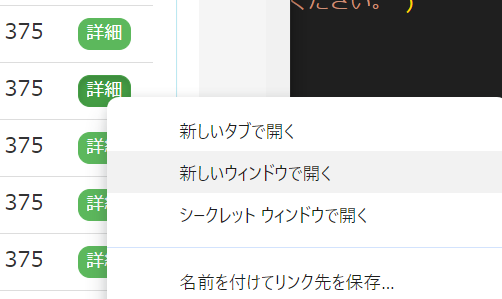
これを繰り返し、各月の購入履歴を取得します。
名前は任意ですが、以下のような名前にしておくことを推奨します。
こうしておけば、日付が古い順にデータが集計されるからです。
集計スクリプトの実行
準備
Pythonスクリプトのため、Pythonのインストールが必要です。
ライブラリとしてBeautiful Soup、pandasも使用するのでpip経由でインストールしておいてください。
pip install pandas beautifulsoup4ソースコード
下記のソースコードをコピーし、適当なPythonスクリプトとして保存します。
今回は「get_rawdata_and_fee_from_htm.py」としました。
import os
import csv
from bs4 import BeautifulSoup
import pandas as pd
from datetime import datetime
# 定数の定義
FOLDER_PATH = 'zaif_tsumitate_data/'
CSV_FILE_NAME = 'zaif_tsumitate_rawdata.csv'
# CSV出力の設定
CSV_SEP = ','
CSV_QUOTING = csv.QUOTE_NONE # フィールドをダブルクォーテーションで囲まない
# フォルダ内のHTMLファイルを探索
html_files = [f for f in os.listdir(FOLDER_PATH) if f.endswith('.html') or f.endswith('.htm')]
# すべての取引データと手数料データを格納するための空のデータフレームを作成
all_data = pd.DataFrame()
fee_data = pd.DataFrame()
# 各HTMLファイルに対して処理を行う
for html_file in html_files:
file_path = os.path.join(FOLDER_PATH, html_file)
with open(file_path, 'r', encoding='utf-8') as file:
soup = BeautifulSoup(file, 'html.parser')
# 手数料情報を抽出
panel_body = soup.find('div', {'class': 'panel-body'})
if panel_body:
# 'お引き落とし日' と '手数料' の情報が含まれるテーブル行を特定し、データを抽出
for row in panel_body.find_all('tr'):
# 各セルに含まれるテキストを取得
cells_header = [cell.get_text(strip=True) for cell in row.find_all('th')]
cells_text = [cell.get_text(strip=True) for cell in row.find_all('td')]
# 「お引き落とし日」と「手数料」が含まれているかを確認
if 'お引き落とし日' in cells_header and '手数料' in cells_header:
# 日付と手数料を抽出
withdrawal_date = cells_text[0] # お引き落とし日
fee_amount = cells_text[2] # 手数料
print(f"抽出した「お引き落とし日」: {withdrawal_date}, 「手数料」: {fee_amount}")
fee_date_formatted = datetime.strptime(withdrawal_date, "%Y-%m-%d").strftime("%m/%d")
transfer_date_formatted = withdrawal_date + " 00:00:00"
# 手数料の行を作成し、fee_dataに追加
tmp = {'買付け日付': fee_date_formatted, '通貨': '手数料',
'買付け金額': fee_amount, '買付け数量': '',
'振替日時': transfer_date_formatted}
tmp = pd.DataFrame(tmp, index=[fee_date_formatted])
fee_data = pd.concat([fee_data, tmp], ignore_index=True)
break # データが見つかったらループを抜ける
# 取引データの抽出と追加
table = soup.find('table', {'class': 'table table-striped'})
if table:
data = []
headers = [header.text.strip() for header in table.find_all('th')]
data.append(headers)
for row in table.find_all('tr'):
cells = row.find_all('td')
if len(cells) > 0:
row_data = [cell.text.strip() for cell in cells]
data.append(row_data)
df = pd.DataFrame(data[1:], columns=data[0])
all_data = pd.concat([all_data, df], ignore_index=True)
# 手数料データを取引データの最後に追加
all_data = pd.concat([all_data, fee_data], ignore_index=True)
# データの重複チェック
duplicates = all_data.duplicated(subset=['通貨', '振替日時'], keep=False)
if duplicates.any():
print("エラー: 重複するデータが見つかりました。データを確認してください。")
else:
# すべてのデータを含むデータフレームをCSVファイルとして保存
all_data.to_csv(CSV_FILE_NAME, sep=CSV_SEP, quoting=CSV_QUOTING, index=False)
print("データが正常に処理され、CSVに保存されました。")
二重計上が発生しないようにデータの重複チェックを入れているのはちょっとしたこだわりです(笑)
スクリプトの実行
zaif_tsumitate_dataというフォルダを作成し、その中に前記したhtmファイルをすべて入れます(filesフォルダは不要)
次に、このフォルダとPythonスクリプトをこのような位置関係で配置します。

Pythonスクリプトを実行します。
python get_rawdata_and_fee_from_htm.pyzaif_tsumitate_rawdata.csv というファイルが生成されます。
生成されたCSVファイルの仕様
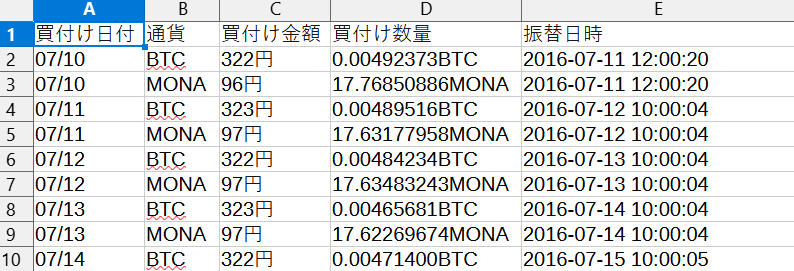
仮想通貨の購入
zaif_tsumitate_data/ フォルダにあるすべてのhtmデータから抽出した「買付け日付」「通貨」「買付け金額」「買付け数量」「振替日時」が当ファイルにまとまっています。
手数料
手数料については、下記の様に一番最後にまとめて記載しています。
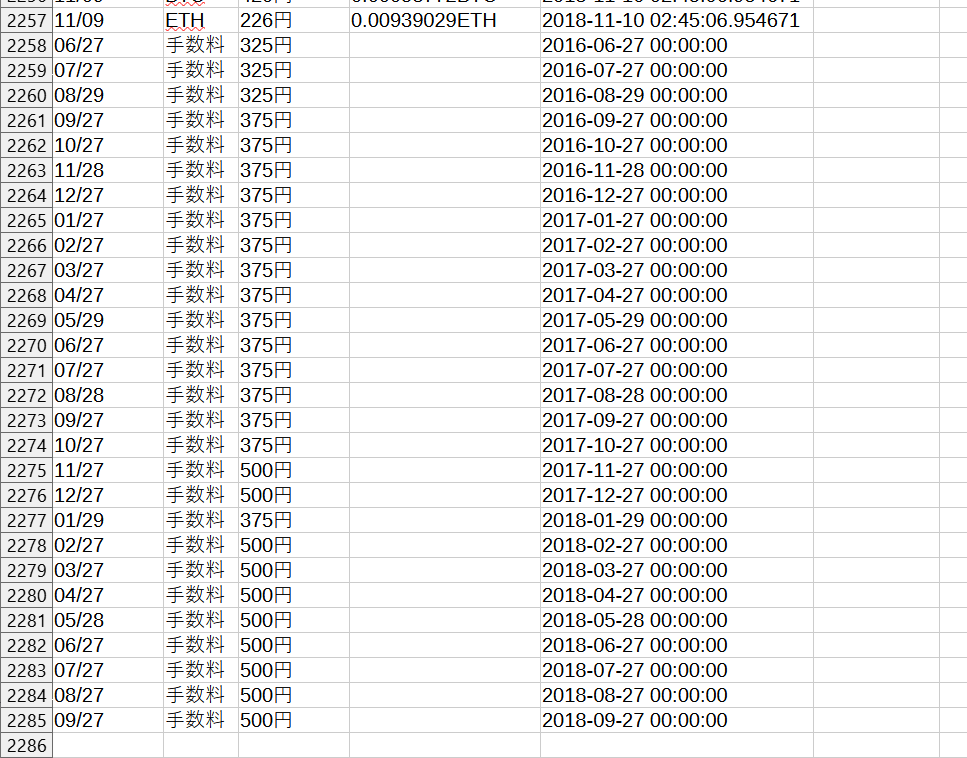
「手数料」の行については、以下の箇所から下記のルールに従って抽出しています。

- 買付け日時:「お引き落とし日」にある記載をMM/DD 形式に変換
- 通貨:「手数料」と表示
- 買付け金額:「手数料」にある記載を転記
- 振替日時:「お引き落とし日」にある記載をYYYY-MM-DD 00:00:00 形式に変換
例えばhtmファイルの記載が上記の画像のようであれば、以下の行が追加されます。
- 買付け日時:07/27
- 通貨:手数料
- 買付け金額:325円
- 振替日時:2016-07-27 00:00:00
おわりに
この状態からであれば、各種仮想通貨の損益計算ツールに取り込めるカスタムファイル(Cryptact)・汎用フォーマット(CryptolinC)の形に簡単に加工できるはずです。
もし何か不具合などありましたら、教えていただけますと幸いです。



コメント